A hacker news submission references the "The black triangle" blog note. I can only backup the author since I have experienced this many time.
For short, with some programs the visible part of it is merely just a black triangle while the invisible part may be complex or required a lot of efforts to achieve. The black triangle is then generally just a simple visual example to prove that the underlying system works.
That is the state of progress of DITP. I'm working to get the black triangle to become visible. In doing so I'm also writing the protocol specification so that the protocol may be reviewed and implemented by third parties in other languages or libraries.
The black triangle is like the first fruits of a fruiterer tree that may, sometime, took a long time to grow up to the point to be able to produce fruits.
|
1 Comment
In the last month I rewrote the IDR prototype from scratch and translated the IDR specification document in English. During this process I made a few enhancements in the IDR encoding. I removed an ambiguity with exceptions decoding in some very unlikely situations. The other change was to integrate the update of IEEE 754 specification in 2008 that now defines four types of floating point values, 2 Bytes, 4 Bytes, 8 Bytes and 16 Bytes. It may take some time until these types reach your desk, but IDR should better stick to the standards. So these will be the floating point encodings supported by IDR. The following figure shows the kernel components of the Distributed Information System, the road map and how far I am today. The items in black are implemented and operational and the items in gray still needs to be implemented. Progress is going clockwise :). 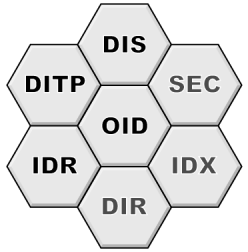 OID An OID is to DIS what the URL is to the web. It is a unique, binary encoded and non reusable reference to an information published in the distributed information system. It was the first tile I designed and implemented. Its simplicity is inversely proportional to the time and effort required to invent it because I had to explore and compare many different possible and existing solutions.  While developing a prototype of DIS to check and validate it, I'm frequently confronted to bugs. After testing many different debuggers on Linux, my conclusion is that none of them is as good as the one of Visual C++ on Windows. So when I have to develop new code which may require debugging, I always develop it with Visual C++. Once it is validated, I move it on Linux. It is time for a new communication duty on my project. It's still in a steady progress but not as fast as I would like. I now use the latest version of libgc. I spent most of my time last month searching the source of a major memory leak. I finally found out that it was caused by STL containers. I changed the code and now use gc_allocator. Even strings had to be changed. Now the client and server run without any memory leak. I thought of changing language (i.e. D) but I didn't want to cut myself away from the C++ community as potential users. So I had to sort out the problem and I finally did. Progress on the design and the prototype implementation is going on. I now have a working prototype for the inter-object communication system. This helps me testing and refining the design. I also regularly review and update the specification documents. The low level C++ wrapper class for cryptographic functions is now finalized. I use XySSL as low level C cryptographic library. XySSL is an open source project of Christophe Devine, a French computer scientist specialized in security. XySSL will support the VIA padlock cryptographic engine which is a good news since VIA servers are cheap, cold and low consuming computers. Progress is good on multiple fronts. Progress is slow because I have daily job and family duties. DITP was designed early, together with IDR. Since IDR is now operational and ready for throughout testing, DITP could be implemented and tested. |
Author Christophe Meessen is a computer science engineer working in France.  Any suggestions to make DIS more useful ? Tell me by using the contact page. Categories
All
Archives
December 2017
|
 RSS Feed
RSS Feed
