
It may be desirable in some situation to be able to assign a numerical reference (integer) to a resource with the particular property that the string representation of the reference preserves the numerical ordering. This blog post presents a numbering method that has this property. The proposed numbering schema achieves this goal and avoids adding zero's or spaces in front of the numbers, thus keeping the strings short. The price to pay is that there will be gaps between the numbering sequence. The numbers in these gaps are invalid numbers in this numbering schema and may be easily recognized and used for error detection.
The problem: You probably experienced that sorting a list of strings representing the integer sequence "1", "2", "3", ..., "10", "11", ... "20", "21", ... yields the weird result "1", "10", "11", ... "2", "20", "21", ... "3", ... This shows up, for instance, when naming files by numbers. We get this result because strings are sorted in lexicographical order which means they are ordered by digit value, one by one from left to right. So in a lexicographical order, "10" is smaller than "2" which is the opposite of the numerical order.
In the situations where this is an unacceptable nuisance we have a set of solutions we could pick one from.
Use a specially crafted sorting algorithm able to detect that it deals with numbers in ASCII representation instead of text strings. In some context, changing the sorting algorithm is not possible (i.e. file names).
Another possibility is to add some zero's or spaces in front of the number in its ASCII representation. The problem with this method is to know how many zero's or spaces should be added. There should be at least as many as the number of digits in the biggest number we need to represent. In some context it is not possible to know the biggest number we will have to dealt with and this introduces a highest value constrain which is preferable to avoid if possible.
The solution: The proposed solution is to use a numbering schema where we simply add in front the number a digits in the number. For instance the number 234 has 3 digits. This number would then be coded as "3123" in the proposed schema where the 3 (shown in bold) is added in front of the number.
The number is valid if the string contains only digits and the first digit is length minus one. The value 0 is represented as 0. For negative numbers, if you need them, the number of digits must be inserted between the minus sign (-) and the number.
There is also an upper limit in the maximum number of digits the number can have. The biggest number that may be represented with this numbering schema is 10 billion minus one.
With this numbering schema, the sequence "1", "2", "3", ..., "10", "11", ... "20", "21" becomes "11", "12", "13", ..., "210", "211", ... "220", "221" with the added digit in front shown in bold. The lexicographical sorting of this number sequence will preserve this order.
The price to pay is that the numbering sequence is not compact. It has gaps containing invalid numbers (i.e. 23, 123,... ). This may be considered an inconvenient but has also the benefit to make it possible to detect errors and invalid values.
Generating such number sequence is trivial as well as checking their validity.
Application example: I "invented" this coding schema when looking for an optimal way to numerically reference resources assigned incrementally for a web service (i.e. userId, documentId, imageId, ....). The numbering provides a direct mapping with a numerical table index value as well as a compact string representation. The size of the reference would grow smoothly as needed with the number of references.
Another application is as document id in NoSQL databases like CouchDB, MongoDB, etc. Keep the id compact and sorted.
Using a Base64 like encoding
A more compact coding would use a base64 like encoding. Conversion between the ASCII and binary encoding would not be as straightforward, but identifiers would be much more compact and still preserve the sorting of ASCII and binary representation.
To generate such encoding, split the binary representation in groups of 6 bits, starting from the less significant bit (right most) toward the most significant bit. Then replace all the left most chunks that have all bits to zero with a single chunk coding the number of 6bits chunks left. For instance ...00000|110010|010011 becomes 000010|110010|010011 because there are only two significant chunks in the number and 2 is encoded with 6 bits as 000010. The last step is to replace each 6 bit chunks in the resulting chunk sequence with the ASCII codes provided in the following table.
The problem: You probably experienced that sorting a list of strings representing the integer sequence "1", "2", "3", ..., "10", "11", ... "20", "21", ... yields the weird result "1", "10", "11", ... "2", "20", "21", ... "3", ... This shows up, for instance, when naming files by numbers. We get this result because strings are sorted in lexicographical order which means they are ordered by digit value, one by one from left to right. So in a lexicographical order, "10" is smaller than "2" which is the opposite of the numerical order.
In the situations where this is an unacceptable nuisance we have a set of solutions we could pick one from.
Use a specially crafted sorting algorithm able to detect that it deals with numbers in ASCII representation instead of text strings. In some context, changing the sorting algorithm is not possible (i.e. file names).
Another possibility is to add some zero's or spaces in front of the number in its ASCII representation. The problem with this method is to know how many zero's or spaces should be added. There should be at least as many as the number of digits in the biggest number we need to represent. In some context it is not possible to know the biggest number we will have to dealt with and this introduces a highest value constrain which is preferable to avoid if possible.
The solution: The proposed solution is to use a numbering schema where we simply add in front the number a digits in the number. For instance the number 234 has 3 digits. This number would then be coded as "3123" in the proposed schema where the 3 (shown in bold) is added in front of the number.
The number is valid if the string contains only digits and the first digit is length minus one. The value 0 is represented as 0. For negative numbers, if you need them, the number of digits must be inserted between the minus sign (-) and the number.
There is also an upper limit in the maximum number of digits the number can have. The biggest number that may be represented with this numbering schema is 10 billion minus one.
With this numbering schema, the sequence "1", "2", "3", ..., "10", "11", ... "20", "21" becomes "11", "12", "13", ..., "210", "211", ... "220", "221" with the added digit in front shown in bold. The lexicographical sorting of this number sequence will preserve this order.
The price to pay is that the numbering sequence is not compact. It has gaps containing invalid numbers (i.e. 23, 123,... ). This may be considered an inconvenient but has also the benefit to make it possible to detect errors and invalid values.
Generating such number sequence is trivial as well as checking their validity.
Application example: I "invented" this coding schema when looking for an optimal way to numerically reference resources assigned incrementally for a web service (i.e. userId, documentId, imageId, ....). The numbering provides a direct mapping with a numerical table index value as well as a compact string representation. The size of the reference would grow smoothly as needed with the number of references.
Another application is as document id in NoSQL databases like CouchDB, MongoDB, etc. Keep the id compact and sorted.
Using a Base64 like encoding
A more compact coding would use a base64 like encoding. Conversion between the ASCII and binary encoding would not be as straightforward, but identifiers would be much more compact and still preserve the sorting of ASCII and binary representation.
To generate such encoding, split the binary representation in groups of 6 bits, starting from the less significant bit (right most) toward the most significant bit. Then replace all the left most chunks that have all bits to zero with a single chunk coding the number of 6bits chunks left. For instance ...00000|110010|010011 becomes 000010|110010|010011 because there are only two significant chunks in the number and 2 is encoded with 6 bits as 000010. The last step is to replace each 6 bit chunks in the resulting chunk sequence with the ASCII codes provided in the following table.
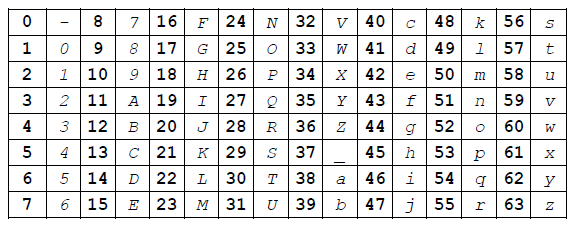
Mapping between chunk's 6 bit binary integer value and ASCII letters used for encoding
The resulting encoding is very similar to Base64 encoding but has the particular properties to preserve the sorting order of the chunk integer value and the associated ASCII value as well as using ASCII codes that may be used in URLs or filenames. Except for the value 0, the ASCII representation will never start with a '-'.
Conversion between the ASCII representation and the binary representation is more complicated, especially when it has to be done by humans. Though a benefit of this coding is that its ASCII representation will be short for small numbers. The ASCII coding will have n+1 letters for numbers with n significant chunks. For up to 24 bit numbers (over 16 millions values), the longest ASCII encoding will be 5 letters.
Conversion between the ASCII representation and the binary representation is more complicated, especially when it has to be done by humans. Though a benefit of this coding is that its ASCII representation will be short for small numbers. The ASCII coding will have n+1 letters for numbers with n significant chunks. For up to 24 bit numbers (over 16 millions values), the longest ASCII encoding will be 5 letters.


 RSS Feed
RSS Feed
