The following two paragraphs are the introductory paragraphs of the document Fallacies of distributed computing (pdf) by Arnon Rotem-Gal-Oz that presents the 8 fallacies of distributed computed.
"Distributed systems already exist for a long tThe software industry has been writing distributed systems for several decades. Two examples include The US Department of Defense ARPANET (which eventually evolved into the Internet) which was established back in 1969 and the SWIFT protocol (used for money transfers) was also established in the same time frame [Britton2001].
Nevertheless, In 1994, Peter Deutsch, a sun fellow at the time, drafted 7 assumptions architects and designers of distributed systems are likely to make, which prove wrong in the long run - resulting in all sorts of troubles and pains for the solution and architects who made the assumptions. In 1997 James Gosling added another such fallacy [JDJ2004]. The assumptions are now collectively known as the "The 8 fallacies of distributed computing" [Gosling]:
While in the process of designing a new distributed information system, it a good idea to check how it position itself regarding these 8 fallacies.
The network is reliable
DIS uses TCP which was designed to be reliable and robust. Reliable means that data is transmitted uncorrupted to the other end and robust means that it may resist to a certain amount of errors. There is however a limit to the robustness of a TCP connection, and in some conditions connection to a remote service may even not be possible.
DITP, the communication protocol of DIS, is of course designed to handle connection failures. Higher level and distributed services will have to take it in account too.
Making a distribute information system robust implies to anticipate connection failures at any stage of the communication. For instance, a flock of servers designed to synchronize with each other may suddenly be partitioned in two or more unconnected flocks because of a network failure, and be connected back together later.
The latency is zero
Latency was a major focus in the design of the DITP protocol because DIS is intended to be used for World Area Network (WAN) applications. DITP reduces latency impact by supporting asynchronous requests. These requests are batched and processes sequentially by the server in the order of emission. If a request in the batch is aborted by an exception, subsequent requests of the batch are ignored. This provides a fundamental functionality to support transactional applications.
In addition to this, DIS may also support the ability to send code to be executed by a remote service. This provides the same functionality as JavaScript code embedded in web pages and executed by browsers, allowing to implement powerful and impressive web 2.0 applications.
With DIS, remote code execution is taken care by services made available by the server manager if he wants to support them. The services may then process different types of pseudo-codes: JavaScript, Haxe, JVM, Python, ... Many different pseudo-codes services may then coexist and evolve independently of DIS. Such functionality is of course also exposed to security issues. See the secure network fallacy for an insight on how DIS addresses it.
Bandwidth is infinite
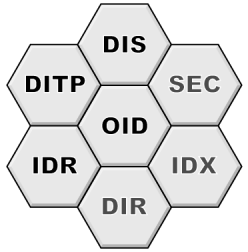
This fallacy is the rational of the Information Data Representation (IDR) design. It uses binary and native data representation. In addition to be very fast and easy to Marshall, it is also very compact.
DITP supports also user defined processing of transmitted data so that compression algorithms may be applied to them. DITP is also multiplexing concurrent communication channels in the same connections, allowing to apply different transmitted data processing to each channel. By choosing the channel the user may decide to compress transmitted data or not.
The network is secure
A distributed system designed for a world wide usage must obviously take security in account. This means securing the transmitted data by mean of authentication and cyphering, as well as authenticating communicating parties and enforce access or action restriction rules.
Communication security is provided by the DITP protocol by mean of the user specified transmitted data processing. As data compression, these can also handle data authentication and cyphering. Different authentication and cyphering methods and algorithms can coexist in DIS and may evolve independently of the DITP protocol.
Authentication and access control may use conventional passwords methods as well as user identification certificates. But instead of using x509 certificates, DIS uses IDR encoded certificates corresponding to instances of certificate classes. Users may then derive their own certificates with class inheritance. They may extend the information carried in the certificate or combine different certificate types together.
An authentication based on password checking or user identity certificate matching doesn't scale well for a world wide distributed system because they need to access a reference database. With distributed services, accessing a remote database introduces latencies and replicating it (i.e. caches) weakens its security by multiplying the number breach points.
The authentication mechanism favored in DIS uses member certificates. These certificates are like club or company member access cards. When trying to access a service, the user present the corresponding certificate and the service needs simply to check the certificate validity.
With such authentication mechanism, the service can be scattered all over the Internet and remain lightweight as is required for embedded applications (i.e. smart phones, car computers, ...). The authentication domain can also handle billions of members as well and easily as a few ones. Member certificates may be extended to carry specific informations and connection parameters.
Topology doesn't change
The ability to handle network topology changes initiated the conception of DIS in 1992. It is thus designed from the start to address this issue in a simple, robust and efficient way. It is not a coincidence that the DIS acronym resembles the one of DNS. DIS is a distributed information system as the DNS is a distributed naming system. DIS uses the proven architecture of the DNS and applies it to generic information with additional functionalities like allowing to remotely manage the information. The DNS is known to be a corner stone of the network topology change solution, as will be DIS.
There is one administrator
As the DNS, DIS supports a distributed administration. Information domain administrator have full liberty and authority in the way they organize and manage their information domain as long as the interface to DIS respects some standard rules. As for the DNS, there will be a central administration that defines the operational rules and control their application. If DIS becomes a broadly adopted system, the central administration will be composed of members elected democratically and coordinated with the Internet governance administration if such structures happens to be created.
Transport cost is zero
The transport cost is indeed not zero but most of it is distributed and shared by the users. There remains however a residual cost for the central services and administration for which a revenue has to be identified. The DIS system will allow to obtain such a revenue and there is a rational reason why it ought to.
Imposing a financial cost to some domains or features of DIS which are limited or artificially limited resources provides a mean to apply a perceptible pressure on its misbehaving users (i.e. spam).
The network is homogeneous
DITP is designed to support different types of underlying transport connections. The information published in DIS is treated like an opaque byte block and may be of any type as well as its description language. It may be XML with its DTD description, binary with C like description syntax, python pickles or anything else. Of course it will also contain IDR encoded information with its Information Type Description.
Conclusion
The conclusion is that DIS, DITP and IDR have been designed without falling on any of the common fallacies. This is partly due to the long maturation process of its conception. While this may be considered as a shortcoming, it may also be its strength since it allowed to examine all aspects wisely with time.
"Distributed systems already exist for a long tThe software industry has been writing distributed systems for several decades. Two examples include The US Department of Defense ARPANET (which eventually evolved into the Internet) which was established back in 1969 and the SWIFT protocol (used for money transfers) was also established in the same time frame [Britton2001].
Nevertheless, In 1994, Peter Deutsch, a sun fellow at the time, drafted 7 assumptions architects and designers of distributed systems are likely to make, which prove wrong in the long run - resulting in all sorts of troubles and pains for the solution and architects who made the assumptions. In 1997 James Gosling added another such fallacy [JDJ2004]. The assumptions are now collectively known as the "The 8 fallacies of distributed computing" [Gosling]:
- The network is reliable
- Latency is zero
- Bandwidth is infinite
- The network is secure
- Topology doesn't change
- There is one administrator
- Transport cost is zero
- The network is homogeneous
While in the process of designing a new distributed information system, it a good idea to check how it position itself regarding these 8 fallacies.
The network is reliable
DIS uses TCP which was designed to be reliable and robust. Reliable means that data is transmitted uncorrupted to the other end and robust means that it may resist to a certain amount of errors. There is however a limit to the robustness of a TCP connection, and in some conditions connection to a remote service may even not be possible.
DITP, the communication protocol of DIS, is of course designed to handle connection failures. Higher level and distributed services will have to take it in account too.
Making a distribute information system robust implies to anticipate connection failures at any stage of the communication. For instance, a flock of servers designed to synchronize with each other may suddenly be partitioned in two or more unconnected flocks because of a network failure, and be connected back together later.
The latency is zero
Latency was a major focus in the design of the DITP protocol because DIS is intended to be used for World Area Network (WAN) applications. DITP reduces latency impact by supporting asynchronous requests. These requests are batched and processes sequentially by the server in the order of emission. If a request in the batch is aborted by an exception, subsequent requests of the batch are ignored. This provides a fundamental functionality to support transactional applications.
In addition to this, DIS may also support the ability to send code to be executed by a remote service. This provides the same functionality as JavaScript code embedded in web pages and executed by browsers, allowing to implement powerful and impressive web 2.0 applications.
With DIS, remote code execution is taken care by services made available by the server manager if he wants to support them. The services may then process different types of pseudo-codes: JavaScript, Haxe, JVM, Python, ... Many different pseudo-codes services may then coexist and evolve independently of DIS. Such functionality is of course also exposed to security issues. See the secure network fallacy for an insight on how DIS addresses it.
Bandwidth is infinite
This fallacy is the rational of the Information Data Representation (IDR) design. It uses binary and native data representation. In addition to be very fast and easy to Marshall, it is also very compact.
DITP supports also user defined processing of transmitted data so that compression algorithms may be applied to them. DITP is also multiplexing concurrent communication channels in the same connections, allowing to apply different transmitted data processing to each channel. By choosing the channel the user may decide to compress transmitted data or not.
The network is secure
A distributed system designed for a world wide usage must obviously take security in account. This means securing the transmitted data by mean of authentication and cyphering, as well as authenticating communicating parties and enforce access or action restriction rules.
Communication security is provided by the DITP protocol by mean of the user specified transmitted data processing. As data compression, these can also handle data authentication and cyphering. Different authentication and cyphering methods and algorithms can coexist in DIS and may evolve independently of the DITP protocol.
Authentication and access control may use conventional passwords methods as well as user identification certificates. But instead of using x509 certificates, DIS uses IDR encoded certificates corresponding to instances of certificate classes. Users may then derive their own certificates with class inheritance. They may extend the information carried in the certificate or combine different certificate types together.
An authentication based on password checking or user identity certificate matching doesn't scale well for a world wide distributed system because they need to access a reference database. With distributed services, accessing a remote database introduces latencies and replicating it (i.e. caches) weakens its security by multiplying the number breach points.
The authentication mechanism favored in DIS uses member certificates. These certificates are like club or company member access cards. When trying to access a service, the user present the corresponding certificate and the service needs simply to check the certificate validity.
With such authentication mechanism, the service can be scattered all over the Internet and remain lightweight as is required for embedded applications (i.e. smart phones, car computers, ...). The authentication domain can also handle billions of members as well and easily as a few ones. Member certificates may be extended to carry specific informations and connection parameters.
Topology doesn't change
The ability to handle network topology changes initiated the conception of DIS in 1992. It is thus designed from the start to address this issue in a simple, robust and efficient way. It is not a coincidence that the DIS acronym resembles the one of DNS. DIS is a distributed information system as the DNS is a distributed naming system. DIS uses the proven architecture of the DNS and applies it to generic information with additional functionalities like allowing to remotely manage the information. The DNS is known to be a corner stone of the network topology change solution, as will be DIS.
There is one administrator
As the DNS, DIS supports a distributed administration. Information domain administrator have full liberty and authority in the way they organize and manage their information domain as long as the interface to DIS respects some standard rules. As for the DNS, there will be a central administration that defines the operational rules and control their application. If DIS becomes a broadly adopted system, the central administration will be composed of members elected democratically and coordinated with the Internet governance administration if such structures happens to be created.
Transport cost is zero
The transport cost is indeed not zero but most of it is distributed and shared by the users. There remains however a residual cost for the central services and administration for which a revenue has to be identified. The DIS system will allow to obtain such a revenue and there is a rational reason why it ought to.
Imposing a financial cost to some domains or features of DIS which are limited or artificially limited resources provides a mean to apply a perceptible pressure on its misbehaving users (i.e. spam).
The network is homogeneous
DITP is designed to support different types of underlying transport connections. The information published in DIS is treated like an opaque byte block and may be of any type as well as its description language. It may be XML with its DTD description, binary with C like description syntax, python pickles or anything else. Of course it will also contain IDR encoded information with its Information Type Description.
Conclusion
The conclusion is that DIS, DITP and IDR have been designed without falling on any of the common fallacies. This is partly due to the long maturation process of its conception. While this may be considered as a shortcoming, it may also be its strength since it allowed to examine all aspects wisely with time.


 RSS Feed
RSS Feed
